Rulers, NER, and data iteration
TLDR
The SpanRuler component of spaCy allows you to create rules to recognize spans or entities within your data. Lj and I created a spaCy project to showcase the functionality of the SpanRuler within a NER pipeline, but when we didn’t see the improvement we were looking for in the initial pipeline evaluation, I looked into the data and found some inconsistencies in the annotations. This led me to go back and create a Prodigy workflow to relabel data to get more consistent annotations. Machine learning is rarely a linear process that magically produces results, and iterating between your models and your data will ensure a solid foundation to build your custom ML solutions on.
Intro
The combination of machine learning with rule-based approaches is a synergy that is often overlooked. However, there are a lot of benefits to creating patterns to recognize your data of interest. It can help speed up the annotation process, allow you to better understand your data, and even improve your pipeline. Rule-based systems and machine learning approaches have their own unique benefits - while the former is often more precise and consistent, the latter generally handles more diverse examples. Together, this can be a really powerful tool.
Within spaCy, rule-based matching has previously been implemented with the EntityRuler, but in v4, we will be deprecating the EntityRuler and replacing it with the SpanRuler. The SpanRuler has the same functionality as the EntityRuler but also allows for overlapping span annotation instead of the typical disjoint named entities defined in doc.ents.
Lj and I worked on a new spaCy project tutorial, spanruler_restaurant_reviews, to showcase the functionality of the SpanRuler as a replacement for the EntityRuler. This project compared an NER model to an NER + SpanRuler pipeline to show the SpanRuler in action. However, when we evaluated the pipelines, we weren’t able to produce the increase in performance we were hoping to see. This led me to dive deeper into the data, find inconsistencies in the annotation, write myself a small set of annotation guidelines and go back and reannotate the dataset with a Prodigy workflow. In this post, we’ll look at how to use the SpanRuler for NER, as well as a complete project overview of what went well, what went wrong, and how we fixed it.
The Project
To showcase the functionality of the SpanRuler as a replacement for the EntityRuler, Lj initially started a project to test the performance of a NER model compared with NER + SpanRuler pipeline. The project uses the MIT Restaurant dataset (Liu, et al, 2013) to determine non-overlapping entities such as Rating, Location, Restaurant_Name, Price, Dish, Amenity, and Cuisine in restaurant reviews.
First, the project trains a NER-only model as our baseline. We then add the SpanRuler component after the NER model in a new pipeline. This allows us to compare the two pipelines and see if the rules improved the pipeline scores.

This project was made using the spaCy project system, which allows us to share the end-to-end workflow and orchestrate training, packaging and serving within a single, reproducible system. If you’re interested in trying out this project yourself, you can simply run spacy project clone tutorials/spanruler_restaurant_reviews, or visit the GitHub repo for more info.
Once you have the project locally, you can run spacy project assets to download the data. Within the data, each token is labeled with 0 , no label, B-<label> , the beginning of an entity, or I-<label>, all other tokens in the entity. To train the spaCy model, we need to turn the data into a format spaCy can work with, so we can run a preprocessing step and then spacy convert on the IOB data. This dataset and others are also available in our span labeling datasets repo.
# example entry in the training dataset
O any
O chance
O i
O can
O get
O a
B-Amenity reservation
O at
O that
B-Amenity fine
I-Amenity dining
O place
O thats
O the
B-Rating top
I-Rating rated
I-Rating on
I-Rating tripadvisor

For our NER model, we have a config with two components to our pipeline, Tok2Vec, and NER. We’re using en_core_web_lg vectors for our Tok2Vec vectors. The train command will generate a baseline NER model to later combine with our SpanRuler component.
Combining NER and SpanRuler
The rules.py file contains the patterns we’ve written to try to improve the scores of the NER model. Within each function, we’ve defined rules relating to a certain topic. Each item in the patterns list is set with a label, the same set of labels the NER model uses. We then have a dictionary of tokens to match. You can find the list of available operators and token attributes for matching in the docs, but be aware of the required pipeline components for each attribute. For example, in order to use the LEMMA attribute, you would need a lemmatizer component within your pipeline. For more on matching, check out our channel on Youtube!
For example, here’s what a rule looks like if we want to capture spans like “within 5 minutes” or “within 12 minutes distance”. This pattern specifies a sequence of tokens where the first three tokens are “within” followed by a digit and “minutes”. The final two tokens, “driving” and “distance”, are optional as indicated by the use of the “?” operator.
# example pattern
def pattern_range_location() -> Rules:
"""Define rules that tell the range of a place."""
patterns = [
{
"label": "Location",
"pattern": [
{"LOWER": "within"},
{"IS_DIGIT": True},
{"LOWER": "minutes"},
{"LOWER": "driving", "OP": "?"}, # optional token
{"LOWER": "distance", "OP": "?"}, # optional token
],
},
]
return patterns
For our NER + SpanRuler pipeline, we have a config with all three pipeline components, Tok2Vec, NER, and the SpanRuler. When we assemble the SpanRuler component with our NER model, there are a few important things to note.
The SpanRuler can produce both spans and entities. Where spans are potentially overlapping and arbitrary, entities have clear token boundaries and are non-overlapping. Since we’re using NER, we’ll want to produce entities instead of spans with the SpanRuler, so we should adjust some settings in the ner_ruler.cfg. The first is to set annotate_ents to True so that the model will save the entities to doc.ents instead of doc.spans.
[components.span_ruler]
factory = "span_ruler"
spans_key = null
annotate_ents = true
ents_filter = {"@misc": "spacy.prioritize_new_ents_filter.v1"}
validate = true
overwrite = false
We then need to specify the patterns. Within the rules.py file, the function restaurant_span_rules will return the complete set of rules we’ve written. This function is attached to the class restaurant_rules.v1 in the registry, which allows us to call it from the ner_ruler.cfg file as a registered function. This method is a bit different from the jsonl files you might find on the spaCy website, Lj’s blog post on this explains why and how in more detail!
With that, we can then run spacy project assemble to assemble the ner_ruler pipeline. If you look at the command, you can see that it’s using spacy assemble and specifying the source for the NER and Tok2Vec components, as well as the python rules file.
Evaluation
If we look at the results, we see an increase in performance for the majority of entities with rules:
| NER only | With Spanruler | |
|---|---|---|
| Price | 81.68 | 83.23 |
| Rating | 78.42 | 78.06 |
| Hours | 64.91 | 65.80 |
| Amenity | 64.26 | 64.96 |
| Location | 82.28 | 82.82 |
| Restaurant_Name | 76.88 | 78.92 |
In the Rating entity, the rules ended up decreasing the scores. This could have been for several reasons, such as a rule for another entity interfering with the entities for Rating or rules that weren’t consistent with the data annotations. I couldn’t be sure until I looked closer at the rules and the data (which I’ll get into more in the next section 😄).
Overall, we did have a better performance for the combined ner and span_ruler pipeline with our set of rules.
| NER only | With Spanruler | |
|---|---|---|
| Precision | 76.39 | 77.06 |
| Recall | 76.64 | 77.40 |
| F-score | 76.52 | 77.23 |
However, this was not as good of an improvement as we had hoped. With over 500 lines of rules, we thought it was a little strange only to see less than a 1% improvement.
I wrote a small script to see what data the NER + SpanRuler pipeline was not annotating, and saw some opportunities for rules that might better the scores - or so I thought. When I wrote these rules, they actually ended up decreasing the scores, much like the Rating label. Then came the next question - why?
Data is tricky
Using the high-tech solution of command-F in the training data, I began to look into some of the examples where I noticed the rules didn’t work. I ended up finding a lot of inconsistencies in how the data was annotated.
Chasing high accuracy scores on datasets isn’t necessarily the best way to solve real-world problems. You could keep throwing bigger and bigger models at it, and they might do better, but that wouldn’t address the underlying problem of inconsistent annotations. As explained in our Applied NLP Thinking blog post, evaluation metrics aren’t everything, and it’s important to understand the impacts on the application or project.
A little tease for the remainder of the post:
So for applied NLP within business processes, the utility is mostly about reducing variance. Humans and models both make mistakes, but they’re very different mistakes. Humans can easily catch mistakes made by a model, and a model can be great at correcting human errors caused by inattention.
- Applied NLP Thinking, Explosion blog
One of the inconsistencies I first noticed was that “from here” was sometimes considered part of the Location label and sometimes not. This messed up our rules because if I included “from here”, it would get about 11 examples in the training data wrong, which is about 40% of the overall examples. The model didn’t know what to think either, which probably decreased its performance as well.
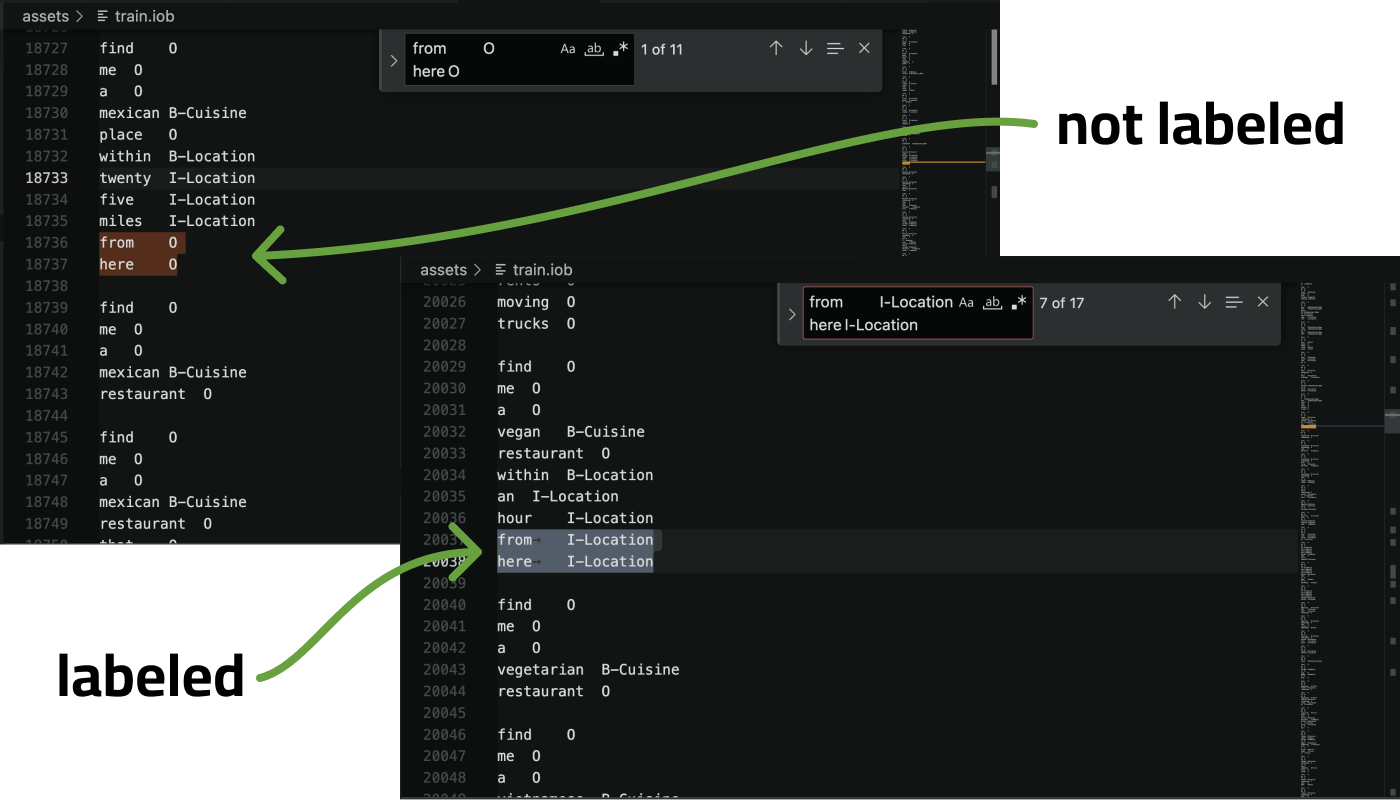
Annotation is hard, and this dataset has a lot of different labels and possibly annotators, and overall consistency has clearly suffered as a result. I knew these inconsistencies were the downfall of some of our rules and possibly decreased the model scores as well.
At this point, I realized the project had only just started. I wanted to go through the data and fix the inconsistent annotations. I decided to start on a Prodigy workflow that would help me look at the predictions by the model to identify and correct inconsistencies within the annotations.
Redo-ing the annotations
The thought process
There are several ways I could have gone about changing the annotations. My main priority here was time. First, I would have to go through some examples to understand patterns and inconsistencies in the datasets, and then I would have to fix the annotations consistently. There are 7662 examples in the training data, and 1521 in the test set. Reannotating everything manually would take a ton of time, and so I decided to explore other options.
There were two ways that I thought of to identify inconsistencies within the data. The first was to come up with as many rules as I could think of that matched with inconsistent annotations, and use Prodigy to specifically flag these examples where the patterns matched using a sorter like prefer_high_scores. The problem with this is that I would need a detailed understanding of the data to figure out the inconsistent spots and then write rules based on those, and this would take a lot of time.
NER models inherently pick up patterns from a dataset so they can label new examples in a similar fashion. This got me thinking - what if I could use the patterns that the NER model we trained was seeing to only annotate instances where the original annotations and the model disagreed?
This process is not 100% ideal. In order to use this method, I would have to adjust the annotations in ways that might make them more similar to the model’s predictions. This would most likely greatly affect the scores of a new model. However, I decided this would be the quickest way to review the annotations and create more consistency, as well as gain a better understanding of the data along the way.
Building a Prodigy workflow
To fix some of the annotations, I used the Prodigy review recipe to compare the model’s output with the original annotations. The review recipe is able to display inputs from multiple “annotators”, in this case, the NER model and our original annotations. Then, the annotator can correct the annotations as needed, and it’s saved into a new dataset.
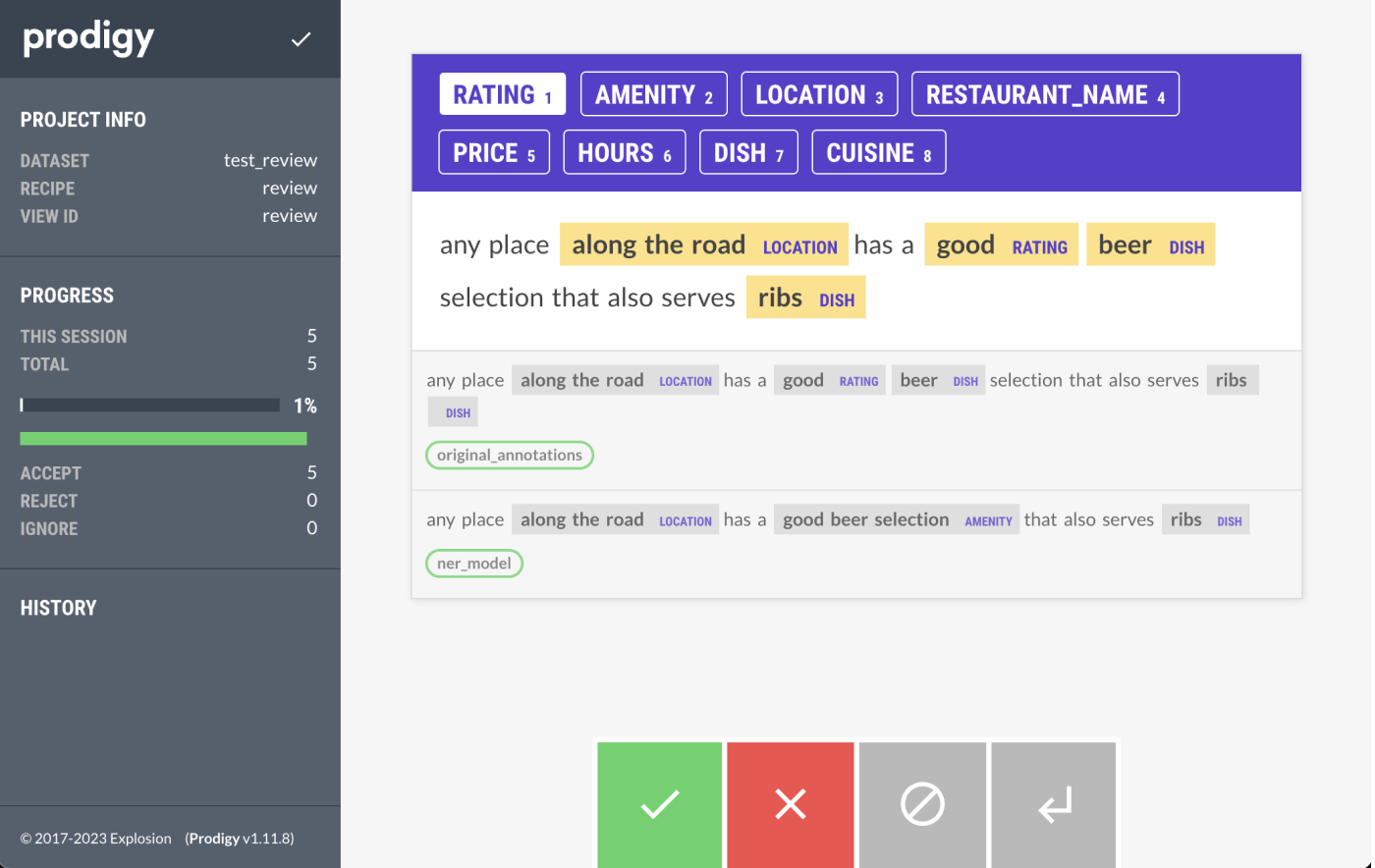
You can find the full script in the project’s GitHub to convert the original data into JSONL formatting with different annotators, but I’ll quickly go through some important parts here.
The file has three different functions, one to mark the original annotations spans, one to mark the NER model annotations, and another to mark the spans recognized by the ruler. For each text, I would generate different examples for the new data with the spans identified by each function and a different _annotator_id and _session_id. Then, I combined all the new datasets into one and generated the new file.
To speed up annotations, I decided to make the ruler’s examples optional to include in the outputted dataset for the review recipe. This would allow me to use the —auto-accept flag of the review recipe if the NER model and the original annotations were the same. This automatically marked around 5,600 out of 7,660 examples as correct, which helped a lot with annotation time. However, based on my initial screening of the data, I know some of the examples it automatically accepted were wrong. For a production-level project, it would probably make sense to go through all the examples or do more pattern matching to pre-select some further candidates for annotation.
Annotating the data
Annotation is hard, and maintaining consistency with even only one person annotating can be really challenging. The more labels and annotators you introduce into a project, the more difficult it becomes to have consistent annotations. There seemed to be a lot of differences on which label certain items should be assigned to, and what tokens should be annotated as part of that label.
In order to keep myself accountable for how I should annotate certain things, I came up with a small set of annotation guidelines. Annotation guidelines are instructions that describe the specific types of information that should be annotated for a task along with examples of each type, and we have a really cool example of these from The Guardian on our blog. I could refer back to this if I were ever confused about how to annotate something, and it allowed me to create rules for annotating. It definitely wasn’t a perfect system, and often I’d find myself going through a few hundred annotations only to realize I should have done something differently.
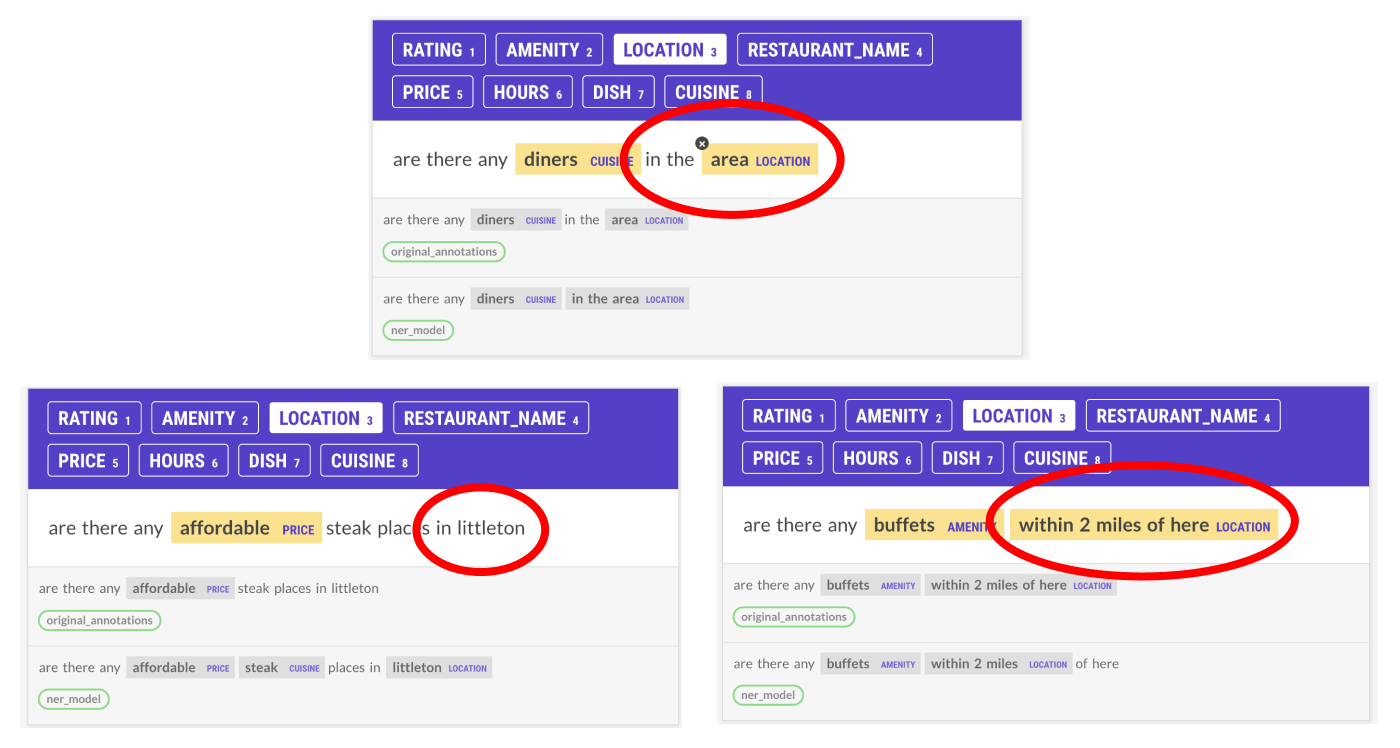
One of the things I found myself having trouble annotating was the Location entities. Depending on the structure of the prepositional phase, it was annotated differently in the original dataset, which made it hard to come up with consistent rules for myself. I had to go through a lot of data before I understood what should be labeled and how. Most of the time, I decided to label the full prepositional phrase, but excluded “of/from here”. The exception was “in/on <location>”, where only the location, not “in” or “on”, would be labeled. These rules covered most occurrences in the original data that were being accepted by the —auto-accept feature, so for simplicities sake, I decided to keep that. If I were to redo all the annotations, I probably would have settled for the entire prepositional phrase in all examples to ensure consistency and simplicity.
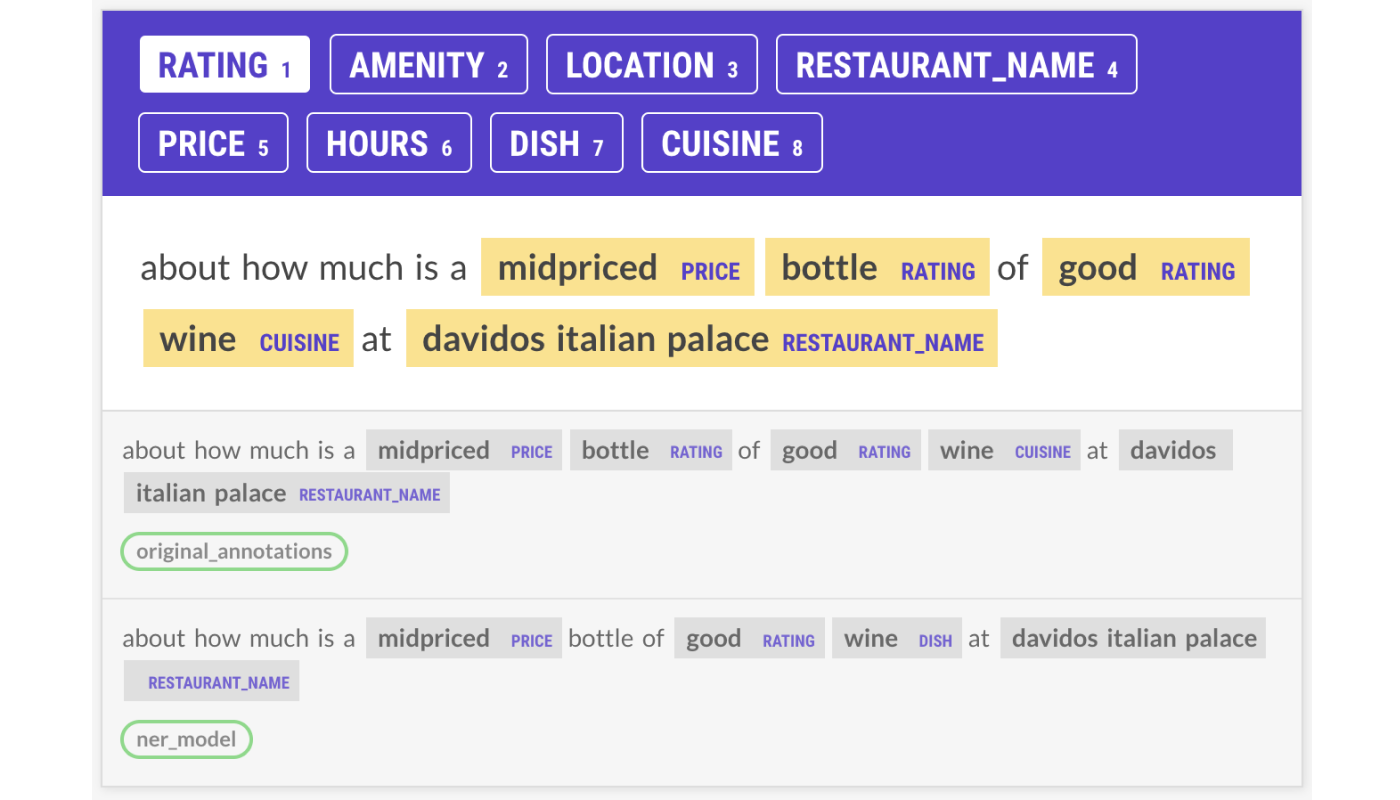
I generally tried to identify patterns the model was picking up on and set that as the default within the annotation guidelines. It’s expected that the model will annotate examples by applying the majority pattern over the inconsistently annotated spans, and if I ever needed to check this on specific cases, I could. With this strategy, I could use the —auto-accept feature without reannotating most of the dataset. In the above example, I completely overwrote the original annotations in favor of the model’s predictions.
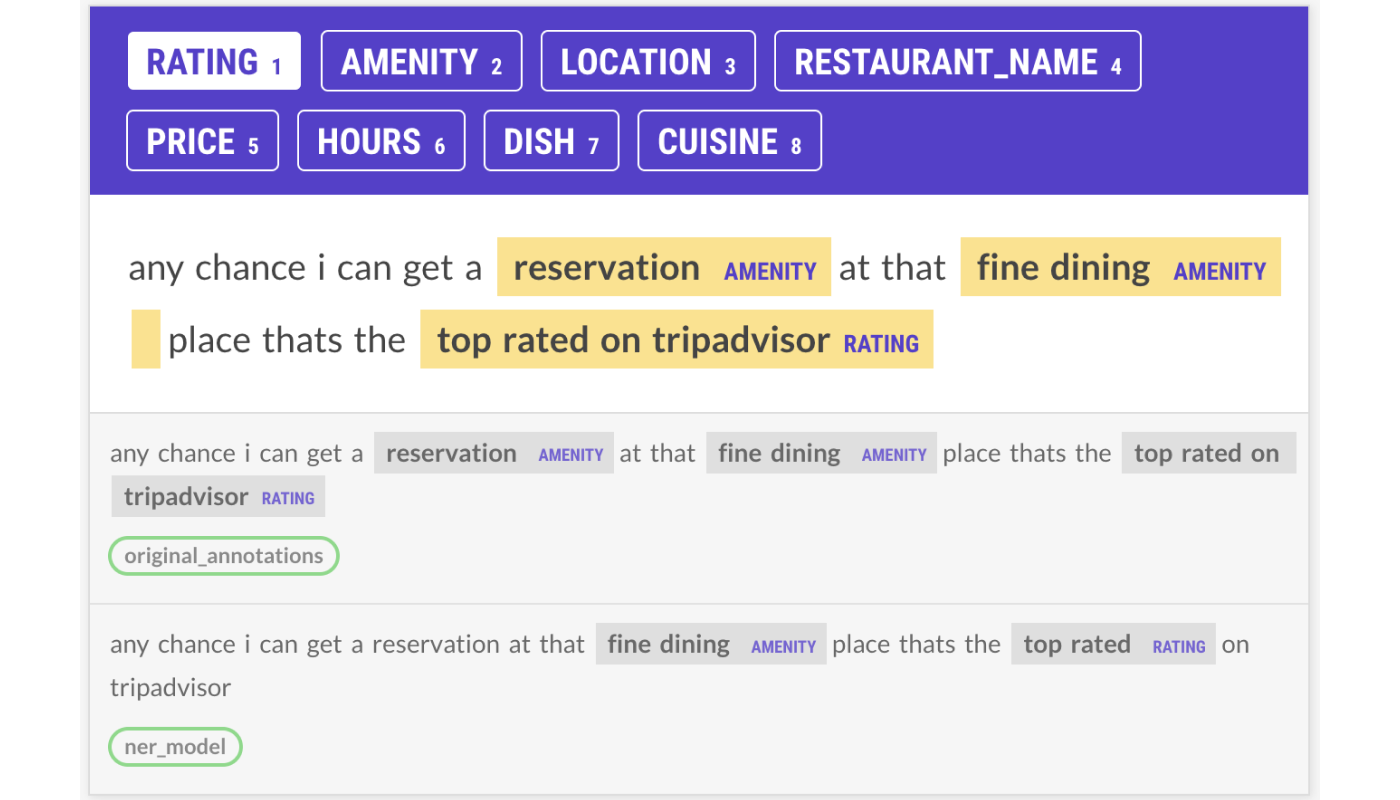
This didn’t always happen, though, and in some cases, the model was wrong. In situations like the one above, I disregarded the model’s suggestions and confirmed the original annotations to be correct. I tried to be as unbiased as possible and took both inputs in mind when labeling and creating my annotation guidelines while still allowing for a consistent output with the —auto-accept feature.
I also found the ruler predictions to be really interesting. More often than not, the ruler wasn’t picking up on much. When it did pick up on something, a lot of the time it was wrong. For example, it would pick up on “breakfast” as an Hours label, but often, “breakfast” was a Cuisine. This led me to go back and change the rules as well, which I’ll talk about briefly in the next section.
Overall, with the added help of the auto-accept, the new annotations took me about 8 hours (around 350 examples per hour) for both the train and the test set.
Training again
After training the base NER model with the new annotations, I took my script from the beginning and reviewed what annotations the model was not getting correct. Some of the annotations that the NER model was missing were inconsistencies that I had been trying to fix in the reviewed data. I wasn’t a perfect annotator and messed up some of the labels, such as whether “high end” referred to the Price or Amentity or Rating label (this was very confusing). This could have been solved by spending more time on understanding the data and better guidelines for annotating.
Overall though, there were a lot fewer items that the NER model was making mistakes on, and several of the labels seemed greatly improved at a first glance. This was expected, in some ways, because I was creating data that was more in line with what patterns the model had found. But it was also nice to see that the model was less confused about what to annotate when and that a lot of the inconsistencies in the entities I had originally noticed weren’t there anymore.
Before looking at the data, we had tried to write rules to pick up Rating entities like “at least 3 stars”. However, these rules ended up decreasing the scores of the NER + Ruler model because sometimes “at least” was labeled, and sometimes it wasn’t. I reannotated almost all of the examples like this because the model was generally not making good predictions, so the model’s annotations were almost never the same as the original annotations.
# example rule
{
"label": "Rating",
"pattern": [
{"LOWER": "at", "OP": "?"},
{"LOWER": "least", "OP": "?"},
{"IS_DIGIT": True},
{"LOWER": {"REGEX": "star(s)?"}},
{"LOWER": {"REGEX": "rat(ed|ing|ings)?"}, "OP": "?"},
],
},
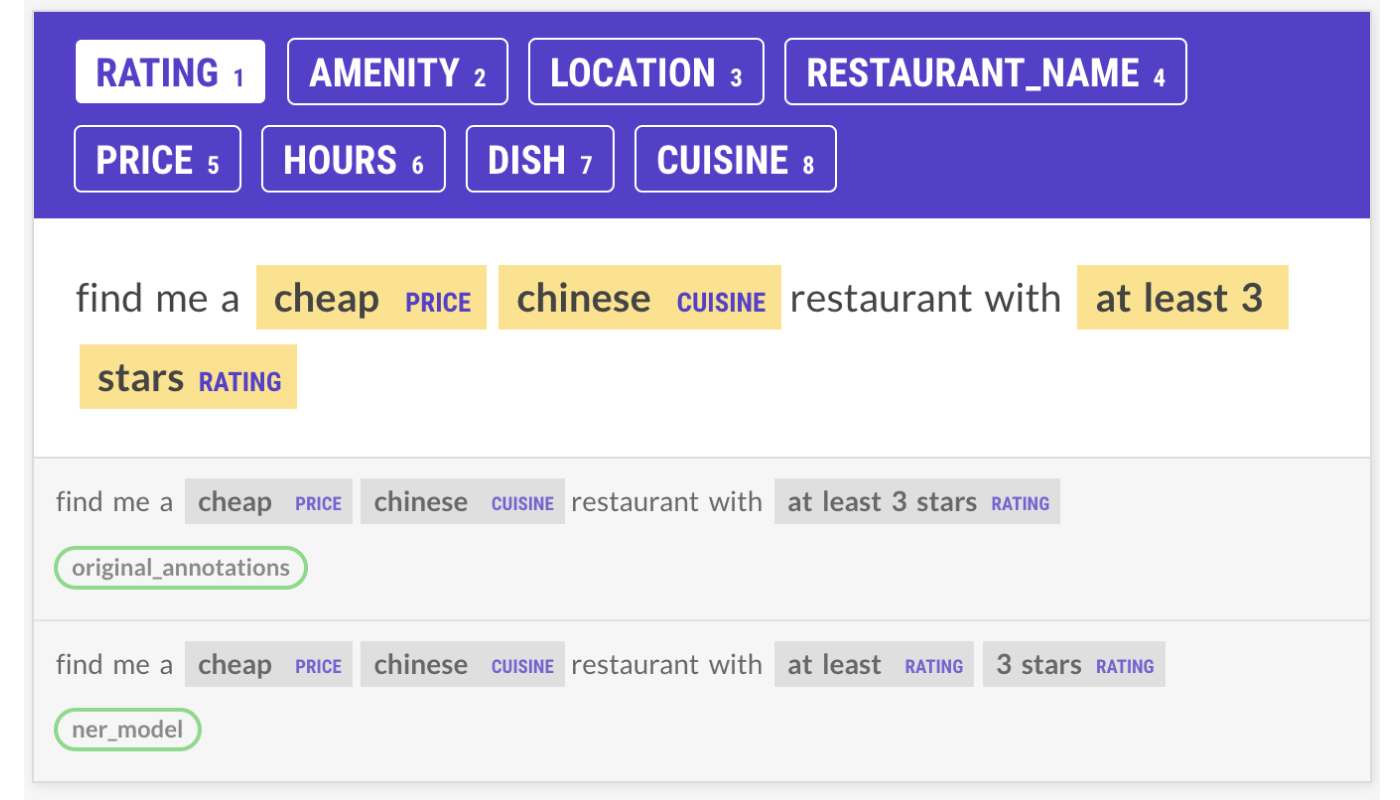
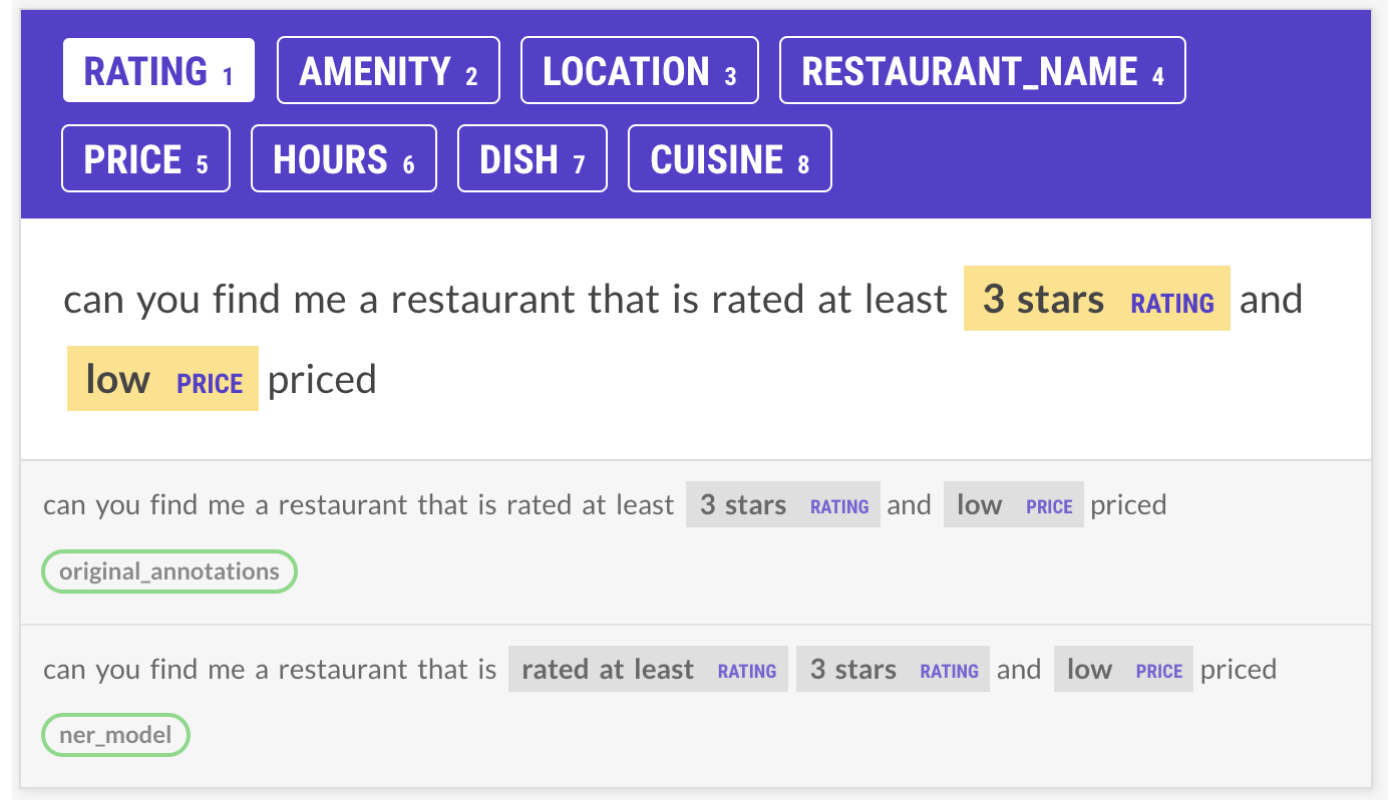
The new model with the revised data was able to consistently annotate these examples! This happened for many of the patterns and meant that we didn’t even need most of the old rules anymore.
I decided to start from scratch and write all new rules for the data. I took the knowledge I had gained from working directly with the data and created patterns that I thought would help better the scores of the model while still trying to make them as general as possible.
After writing the rules, I ran the spacy project run evaluate_review command, and had a look at whether my experiment was successful…
Evaluation (part 2)
As expected, the overall performance of the model was better. This is both because I adjusted the annotations to be more in line with the model and because of better consistency. Again, there are some downsides to this, but iterating on and exploring your data often can lead to good results - and that’s the important message here (and also in this awesome post).
| Without reviewed annotations (NER + SpanRuler) | With reviewed annotations (NER + SpanRuler) | |
|---|---|---|
| Precision | 77.06 | 88.86 |
| Recall | 77.40 | 88.10 |
| F-score | 77.23 | 88.48 |
Beyond the overall model performance, though, I was also able to get more of an impact with rules than I had been able to before. The new rules increased the performance of all the entities, and I had to worry a lot less about decreasing the performance. This meant less iteration on the patterns and better performance with fewer rules.
| NER only | With Spanruler | |
|---|---|---|
| Price | 87.00 | 87.25 |
| Rating | 89.39 | 92.55 |
| Hours | 82.12 | 82.52 |
| Amenity | 80.95 | 83.07 |
| Location | 92.03 | 92.70 |
| Restaurant_Name | 82.90 | 87.48 |
| Cuisine | 90.00 | 91.09 |
| Dish | 83.05 | 85.66 |
| NER only | With Spanruler | |
|---|---|---|
| Precision | 87.05 | 88.86 |
| Recall | 86.31 | 88.10 |
| F-score | 86.68 | 88.48 |
Conclusion
Building custom machine learning solutions is not a linear process. Most often, different parts of your pipeline will cause you to circle back and iterate on other parts to improve the overall whole. The process looks less like this:

and more like this:
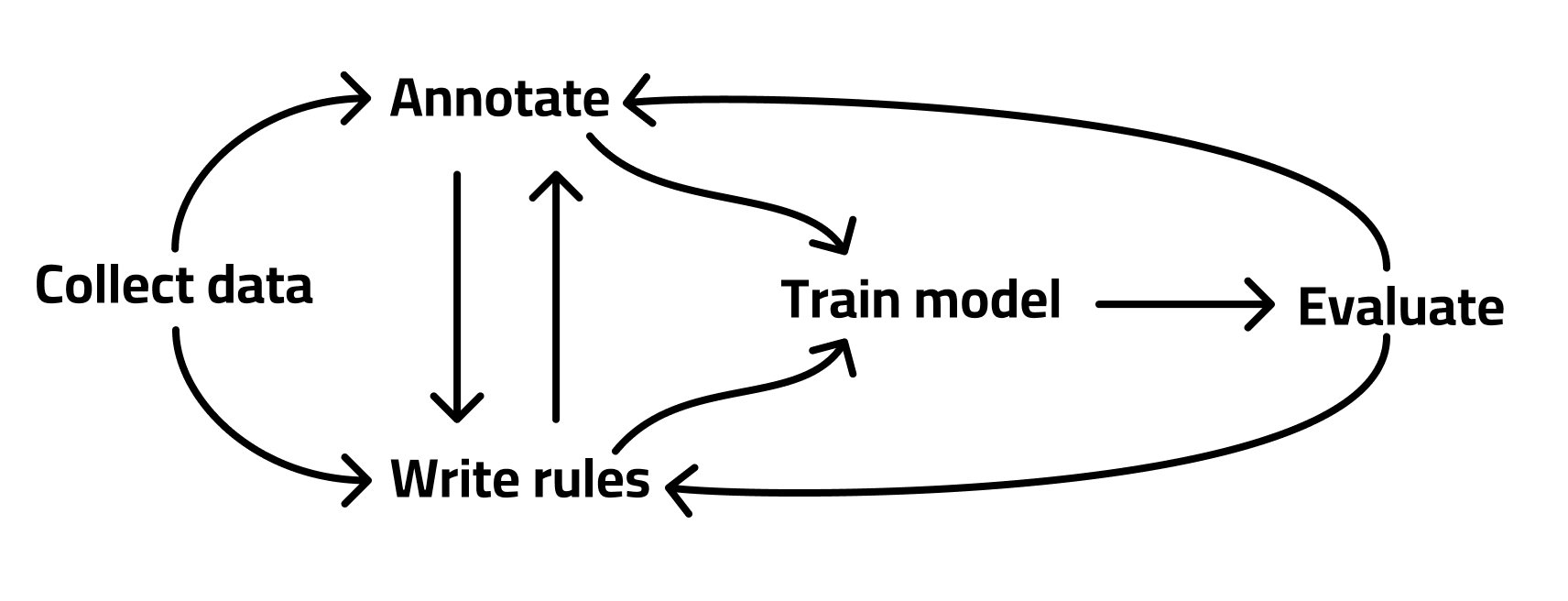
This whole process is similar to how we approach our consulting with spaCy Tailored Solutions, and I honestly think it works really well. Building good solutions to complicated problems requires intimate knowledge of every part of the pipeline, including your data. This is another cool thing about the SpanRuler component too. By coming up with rules to catch annotations that might otherwise be missed or improve your annotation process, you gain more experience with what your data actually looks like and knowledge about potential limitations and solutions.
Although, there might be some truth in the saying, “ignorance is bliss”. It would be so much easier if we could just plug some random data into our machine learning model and magically get a good output. As soon as you dive into the meaty bits and pieces, everything gets a lot more complicated. However, situations like these emphasize how important it is to understand your data before you try and throw machine learning solutions onto it. ML isn’t magic - it’s not a solve-all, limited-effort tool. It requires deep understanding and iterative effort to create robust solutions to real-world problems.